





1. 서론
시뮬레이션을 통한 가상 시험은 제품 개발에 매우 유용하다. 주어진 제품 설계안을 기반으로 시뮬레이션을 수행하고, 만약 목표 성능을 만족하지 않을 경우 목표 성능이 만족할 때까지 개선 작업을 반복할 수 있다.이를 통해 실제 현장 시험에 비해 소요 비용 감소 및 개발 기간 단축을 효과적으로 실현 가능하다. 일례로, 차세대 차량 개발에 충돌, 구조, 열, 유동, 전자기 해석 등 다양한 시뮬레이션 기법을 적극적으로 활용하여 신차 개발 기간은 줄이고, 반면 상품성은 높이고 있다.

그림 1 시뮬레이션 해석을 이용한 다양한 공학 시스템 성능 예측
이와 같은 시뮬레이션 해석을 이용한 가상 시험의 유용성은 두말할 필요가 없을 것이다. 그런데, 그림 2과 같이 만약 현장 또는 실험실에서 시뮬레이션 해석 결과와 시험 결과가 서로 다르다면 과연 어떤 결과를 더 신뢰해야 할 것인가?
이 경우 필자의 개인적 경험에 따르면 대부분의 사람들은 (심지어 해석 담당자 조차도) 시험 결과를 더 신뢰한다. 이와 같이 지금까지 많은 노력에도 불구하고, 실제 제품의 거동을 정확하게 모사하는 시뮬레이션 모델을 개발하는 것은 여전히 매우 어려운 작업이다.
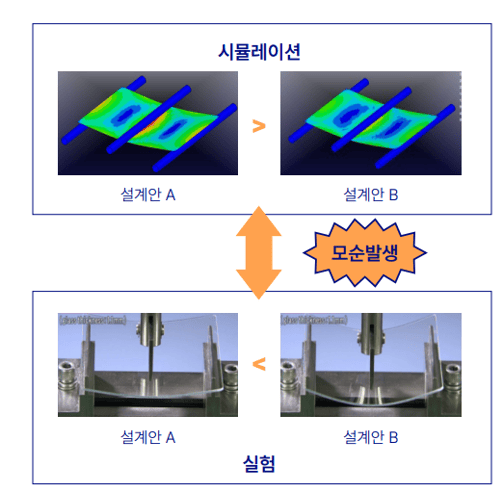
그림 2 시뮬레이션 결과와 실험 결과가 서로 다른 경우 과연 어떤 결과를 믿어야 할까?
시뮬레이션 모델의 예측 유효성을 판단하기 위해 모델 검증 및 검정(Model Verification and Validation; Model V&V) 절차가 사용 되고 있다. 모델 검증(Model verification)이라는 것은 시스템 물리적 거동을 모사하는 지배 방정식을 시뮬레이션 모델이 잘 따르도록 만들어졌는지를 확인하는 작업이다.
예를 들면 시뮬레이션 모델 코드가 정확하게 입력 되어 에러가 발생하지 않고, 입출력 값들의 유효숫자 개수가 적절히 선정되어 계산 과정에서 발생하는 오차가 허용 수준 이하인지 판단하는 것이다.
반면, 모델 검정(Model Validation)이라는 것은 만들어진 시뮬레이션 모델이 주어진 환경에서 시험 결과를 정확하게 예측할 수 있는지를 확인하는 작업이다. 모델을 검정하기 위해서는 그림 3과 같이 주로 세 가지 단계를 거친다.
첫 번째 모델 보정 단계에서는 시뮬레이션 모델 결과와 시험 결과가 일치하도록 조정하는 것이다. 대표적인 방법으로는 재료 탄성 계수와 같은 모델 변수 값을 적절하게 변경하는 것이다. 두 번째 유효성 확인 단계에서는 시뮬레이션 결과와 시험 결과가 얼마나 일치하는지 그 정도를 평가한다.
그 정도가 허용 가능한 수준이라면 시뮬레이션 모델을 제품 성능 예측에 활용하는 것에 적합하다 판정하고 모델 검정은 완료된다. 그렇지 않고 모델이 부적절하다고 판정이 되면, 세 번째 모델 개선 단계를 진행하게 된다.
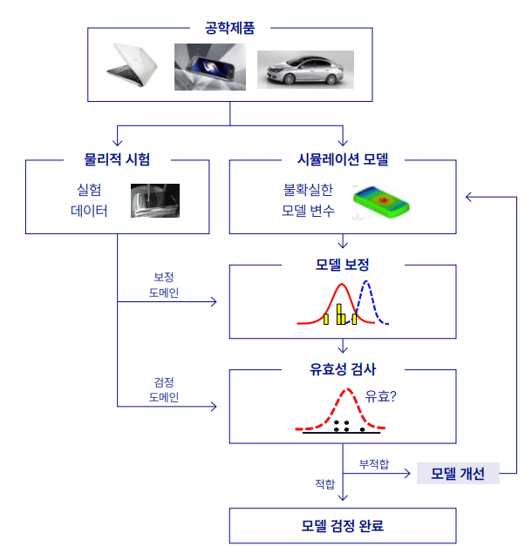
그림 3 시뮬레이션 결과와 실험 결과가 서로 다른 경우 과연 어떤 결과를 믿어야 할까?
2. 모델 보정
모델 보정이란 시험 결과와 시뮬레이션 결과를 일치시키기 위해 계산 모델의 미지 모델 변수 값을 조정하는 작업이다. 재료 물성, 제품 치수, 환경 및 운영 부하와 같은 요소들은 보통 무작위성을 가지고 있기 때문에 불확실성이 발생한다. 이러한 불확실성은 우리가 정확한 값을 알 수 없기 때문에 발생한다.
예를 들어, 고무 재질의 진동 흡수제의 경우 재료 물성을 정확히 알고 있다 하더라도, 운영 조건에 따라 실제 온도 분포가 달라질 수 있으므로 시뮬레이션 모델에 사용할 변수 값을 정확하게 설정하기 어렵다. 또한 대량 생산 제품의 경우 제작 여건상 각 제품들 간 치수 차이는 필연적으로 발생하는데 내가 실험에 사용한 시편의 정확한 치수를 측정하기 보다는 표준 치수를 시뮬레이션 모델에 사용하는 것이 대부분일 것이다. 따라서, 이러한 변동성으로 인해 미지 모델 변수에 대한 조정이 필요할 수 있다.
실험 결과와 시뮬레이션 결과 값을 일치시키기 위해 임의의 모델 변수 값들을 단순히 조정하게 되면, 예측 성능에 오히려 악영향을 미칠 수 있다. 예를 들어, 그림4에서 보다시피 결정론적인 시뮬레이션 계산 결과인 O 표시와 1회의 실험에서 획득한 결과인 파란색 X 표시가 서로 일치하도록 모델 변수 값을 임의로 조정하면 모델의 예측 능력을 오히려 악화시킬 수 있다.
그림 4에서 보정 전에 두 개의 분포가 대략적으로 잘 일치하고 있다. 그러나 단순히 두 개의 점이 일치하도록 보정을 거친 결과 전체적으로 두 개의 분포가 오히려 더 일치하지 않게 되어 버렸다. 실험과 시뮬레이션 모델은 보통 서로 다른 불확실성을 가지고 있고, 시뮬레이션 모델이 실제 시스템의 동작을 완벽하게 모사할 수 없는 경우가 많다.
따라서, 단일 실험 결과와 결정론적인 계산 결과 간의 단순한 일치를 위해 임의의 모델 변수를 조정하는 것은 의도하지 않게 잘못된 결과로 이어질 수 있다
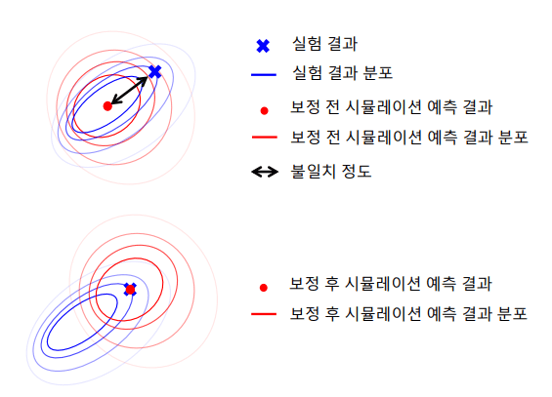
그림 4 모델 변수 값을 임의로 조정하여 보정하면 의도하지 않은 결과가 발생 가능.
결정론적 모델 보정 보다는 통계적 모델 보정이 이러한 가능성을 감소시킬 수 있음.
이러한 상황을 방지하기 위해서는 통계적 모델 보정을 여러 실험 결과와 함께 수행해야 한다. 여러 실험 결과를 활용하여 모델을 보정함으로써, 평균과 변동과 같은 통계적 지표를 일치시킴으로써 모델을 더 정확하게 조정할 수 있다. 통계적 모델 보정은 모델이 서로 다른 다양한 조건에서 더 일관된 예측을 할 수 있도록 도와주며, 예측의 신뢰성을 향상 시킬 수 있다. 이는 모델의
😥 미리 보기는 여기까지!
내용을 이어서 보고 싶다면,
아래 정보를 입력해 주세요.















